CNN - 은닉층 추가
컨볼루션 신경망(CNN)은 입력된 이미지에서 다시 한 번 특징을 추출하기 위해 커널(슬라이딩 윈도)을 도입하는 기법입니다.
시각적 영상을 분석하는 데 사용되는 다층의 피드-포워드적인 인공신경망의 한 종류이다. 필터링 기법을 인공신경망에 적용하여 이미지를 효과적으로 처리할 수 있는 심층 신경망 기법으로 행렬로 표현된 필터의 각 요소가 데이터 처리에 적합하도록 자동으로 학습되는 과정을 통해 이미지를 분류하는 기법이다. [네이버 지식백과]

이미지가 다음과 같은 파란색의 값을 가지고 있고 초록색의 커널을 갖고 있다고 해봅시다.
CNN의 적용과정은 다음과 같습니다. 커널을 파란색 값에 겹쳐 이미지값과 커널값을 곱한 후 계산된 수를 모두 더하면 됩니다.

이렇게 말이죠. 그럼 결과는 어떻게 되냐면

이렇습니다.
이런 과정으로 새롭게 만들어진 층을 합성곱 층이라고 합니다. 합성곱 층을 만들면 이미지의 특징을 대략적으로 추출해서 학습을 할 수 있습니다. 커널을 여러 개 만들명 당연히 여러 개의 합성곱 층이 생성되겠죠?
앞에서 짠 코드에 CNN을 추가해봅시다.
model.add(Conv2D(32, kernel_size=(3,3), input_shape=(28, 28, 1), activation=('relu'))Conv2D에 4개의 인자가 들어갔는데요
1. 커널 개수
2. kernel_size: 커널 크기
3. input_shape: (행, 열, 색상 or 흑백)
if (image == color) return 3
else if (image == black&white) return 1
4. activation: 활성화함수
입니다.

이렇게 될거에요.
CNN을 추가하긴 했는데 데이터가 뭔가ㅏㅏㅏ 아직 커요.
다시 축소하기 위해서 풀링(pooling)을 해보겠습니다.
풀링기법에는 정해진 구역 안에서 최대값을 뽑아내는 맥스 풀링(max pooling)과 평균 값을 뽑아내는 평균 풀링(average pooling) 등이 있습니다.
맥스풀링은 다음과 같습니다.

이런 이미지가 있을 때

맥스 풀링으로 구역을 나누고

가장 큰 값을 추출합니다.
model.add(Maxpooing2D(pool_size=(2,2)))이게 코드고
pool_size는 풀링 창의 크기입니다.

이미지 크기를 줄였으니 노드를 줄여 과적합을 잘 피해보도록 하죠.
드롭아웃(drop out)은 은닉층에 배치된 노드 중 일부를 임의로 꺼 주는 것입니다.
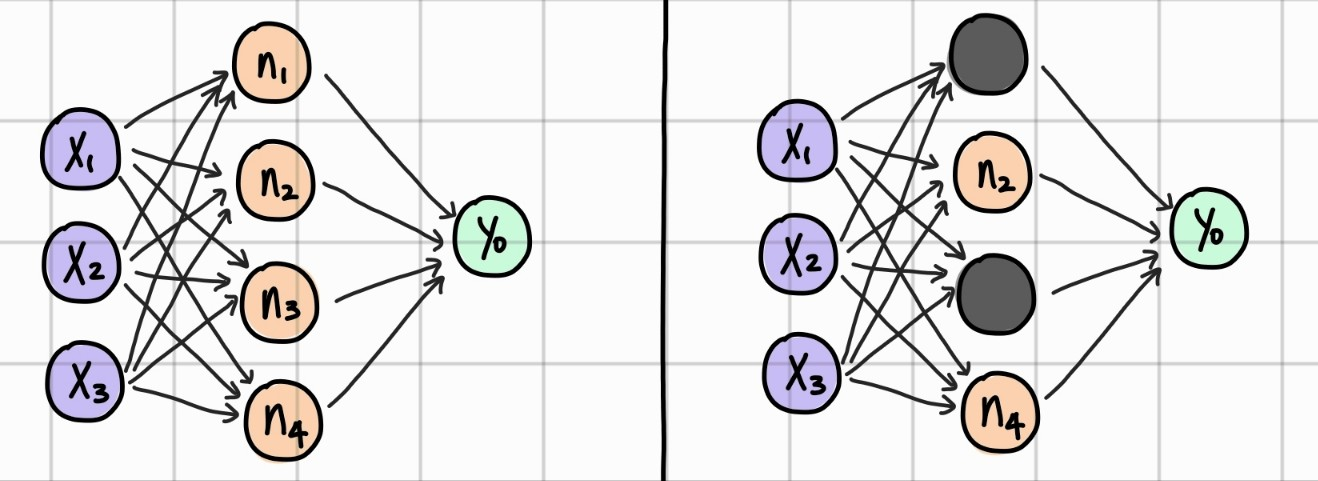
랜덤으로 노드를 꺼주면 학습데이터에 지나치게 치우쳐서 학습되는 과적합을 방지할 수 있다고 합니다.
model.add(Dropout(0.25))25%의 노드를 끄는 코드입니다.
Dense로 기본 층에 연결하고 합성곱층과 맥스풀링이 2차원 배열을 다뤘기 때문에 1차원 배열로 바꾸어 주겠습니다.
model.add(Flatten())
최종적으로 이렇게 나오고 전체 코드를 보겠습니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
import numpy as np
#MNIST 데이터 불러오기
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32')/255
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32')/255
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
#모델 구조 설정
model = Sequential()
model.add(Conv2D(32, kernel_size=(3,3), input_shape=(28, 28, 1), activation='relu'))
model.add(Conv2D(64, kernel_size=(3,3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(10, activation='softmax'))
#모델 컴파일
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#모델 최적화
modelpath = "./MNIST_MLP.hdf5"
checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True)
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=10) # 10번 이상 모델 성능이 향상되지 않으면 학습 중단
#모델 실행
history = model.fit(X_train, y_train, validation_split=0.25, epochs=30, batch_size=200, verbose=0, callbacks=[early_stopping_callback, checkpointer])
#테스트 정확도
print("\n Test Accuracy: %.4f" %(model.evaluate(X_test, y_test)[1]))
#검증셋과 학습셋의 오차 저장
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
#그래프
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()학습이 생각보다 오래 걸렸습니다.
2분에 1번? 정도
으ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅁ
쓰면서 공부하고 있었는데 저거 돌리고 약 30분 후에 오겠습니다.

오 정확도가 0.9918 로 더 높아졌네요
중간에 끊겼지만 정확도가 올라간 모습을 볼 수 있었습니다.