자연어 처리...! 꼭 공부하고 싶었던 것 중 하나 입니다.
원리는 나중에 따로 공부하고 오늘은 코드를 보려고 합니다.
자연어란 우리가 평소에 말하는 음성이나 텍스트를 의마합니다.
자연어 처리(NLP)는 자연어를 컴퓨터가 인식하고 처리하는 것이겠죠.
컴퓨터는 자연어를 바로 받아들이지 못하기 때문에 수치로 된 데이터로 바꾸는 가공이 필요합니다.
1. 텍스트의 토큰화 (tokenization)
2. 단어의 원-핫 인코딩 (one-hot encoding)
3. 단어 임베딩 (word enbedding)
세 가지 과정을 거치는데 먼저 '텍스트의 토큰화'를 해보도록 하겠습니다.
1. 텍스트의 토큰화
가장 먼저 텍스트를 잘게 나눠야 합니다. 입력할 텍스트가 준비되면 이를 문장별, 단어별, 형태소별로 나눌 수 있는데, 이렇게 작게 나누어진 하나의 단위를 토큰(token)이라고 합니다. 텍스트를 나누는 과정은 토큰화(tokenization)이라고 합니다.
코드로는
from tensorflow.keras.preprocessing.text import text_to_word_sequence
text = 'Like bright stars 너의 모든 별빛으로 물들이게'
result = text_to_word_sequence(text)
print("\n원문:\n", text)
print("\n토큰화:\n", result)
이렇게 됩니다.
텍스트의 토큰화는 가장 많이 쓰이는 전처리 과정입니다.
여러 가지를 많이 할 수 있는데 '단어의 가방(Bag-of-Words)'라고 하는 각 단어가 몇 번이나 쓰이는지도 알 수 있습니다.
한 곡의 가사를 가져와서 이것을 진행해 볼까요
가사는 원위의 별을 가져와 보았습니다.
from tensorflow.keras.preprocessing.text import Tokenizer
docs = ['이대로 작은 문을 열면',
'꿈꾸던 곳이 눈앞일까?',
'눈이 부시게 별이 가득한 밤',
'너와 나 둘만 남게 될까?',
'수놓은 이 세상 속에',
'비밀스러운 저 별 안에',
'너와 가볼게',
'길고 긴 밤이 새도록',
'너의 눈을 맞춰 네 곁을 지킬게',
'너에게 모든 걸 맡긴 채',
'운명에 널 약속해',
'우리 저 별 안에 도착할 때 너를 찾아낼게',
'오랜 기다림의 끝에',
'허락된 이 우주 안에',
'그때 다시 우연처럼',
'너의 곁에 있을게',
'우린 같은 시간을 향해',
'저만치의 별도',
'나를 향해 밝게 비춰 부른다',
'하나엔 눈을 감고',
'둘엔 소원을',
'셋엔 내가 네 전부길 원해 yeah',
'평소와 같은 느낌도',
'너와 함께면 다를까?',
'별자리를 쫓아',
'네게 닿으면 새롭던 운명이 번져',
'수많은 별들을 따라',
'밤하늘에 그린 너의 모습 기억해']
token = Tokenizer() #토큰화 함수
token.fit_on_texts(docs) #적용
print('\n단어 카운트:\n', token.word_counts)
'너'를 가리키는 키워드는 12번, '별'이 6번 들어간 단어들이 많습니다. 그리고 이 곡은 하늘이 정해준 운명적인 만남을 별에 비유한 곡이라고 합니다. 왜 많이 나왔는지 알겠죠?
그럼 문장을 세어볼까요?
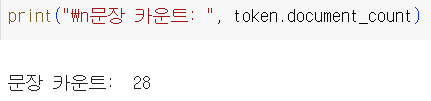
각 단어들이 몇 개의 문장에서 나오는지도 확인해 보면
print('\n각 단어가 몇 개의 문장에 포함되어 있는가:\n', token.word_docs)
인덱스 값을 출력해보면
print("\n각 단어에 매겨진 인덱스 값:\n", token.word_index)
이렇게 나옵니다.
오늘은 텍스트의 토큰화와 활용을 해보았습니다.
참고: [모두의 딥러닝]
'프로그래밍 > 인공지능' 카테고리의 다른 글
| NLP - 긍정, 부정 예측하기 (0) | 2023.07.24 |
|---|---|
| NLP - 원-핫 인코딩, 단어 임베딩 (0) | 2023.07.23 |
| CNN - 은닉층 추가 (0) | 2023.07.22 |
| CNN - 기본 프레임 (0) | 2023.07.19 |
| 합성곱 신경망(Convolutional neural network) - 데이터 전처리 (0) | 2023.07.19 |



