이번글에서는 은닉층에 대해 좀 더 알아보려합니다. 이전 글들에 은닉층을 넣어서 딥러닝 모델을 만들고 그 은닉층안에서는 가중치가 부여되고 수정되는 과정, 즉, 가중치의 업데이트가 일어나는데 이 과정을 공부해보도록 하겠습니다.

단일 퍼셉트론에서는 경사하강법을 사용할 수 있습니다. 경사하강법은 저번 글에서 언급했듯이 임의의 가중치를 선언하고 결과값을 이용해 오차를 구한후 이 오차가 최소가 되는 지점으로 이동하는 것이었습니다. 그리고 이 오차가 최소가 되는 지점은 기울기가 0인 지점이었습니다. 그림을 보면 결과값을 실제값과 비교한 후 가중치를 수정하고 있습니다.
그렇다면 다층 퍼셉트론에서는 어떻게 해야할까요?
다층 퍼셉트론은 은닉층이 존재하기 때문에 두번의 경사하강법을 실행해야 합니다. 위의 그림처럼 결과값을 실제값과 비교한 후 출력층의 가중치를 수정하고 은닉층의 가중치를 수정하는 과정을 거칩니다.
좀 더 자세히 들어가볼까요?
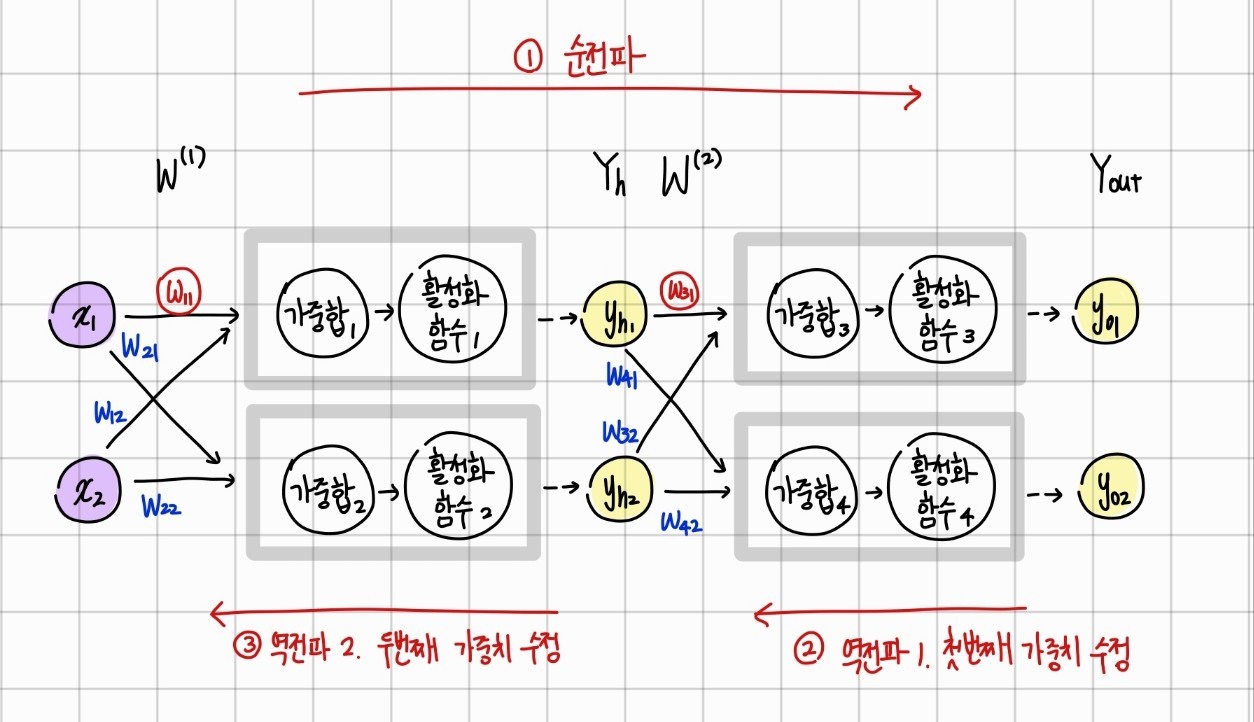
1. 순전파가 일어나는데 이 과정을 통해 가중치의 초기값이 정해집니다. 초기값의 가중치로 만들어진 값과 실제 값을 비교해 출력층의 오차를 계산합니다.
2. 오차를 최소화하기 위해 첫번째 가중치 수정합니다.
3. 두번째 가중치를 수정합니다.
첫 번째 가중치인 $w_{31}$을 업데이트한다고 할 때 경사하강법에서 한 것처럼 오차공식을 구하고 $w_{31}$에 대해 편미분하여 업데이트합니다. 두 번째 가중치를 업데이트할 때도 같은 방법으로 진행하고 $w_{11}$을 업데이트합니다. 업데이트에는 출력값과 실제값을 비교해 오차를 구하는 이러한 과정을 거쳐야하는데 은닉층은 겉으로 들어나지 않으므로 이 값을 알 수 없습니다. 오차를 구할 수 있는 출력값도 없다는 것이 되는 거죠. 이 문제는 출력층의 오차를 다시 이용하여 해결합니다. 오차 두 개를 모두 편미분하여 정리하면 다음과 같습니다.
$$ (첫 번째 가중치 업데이트 공식) = (y_{o1}-y_{실제 값}) · y_{o1}(1-y_{o1}) · y_{h1}$$
$$ (두 번째 가중치 업데이트 공식) = (\delta y_{o1}+\delta y_{o2} · w_{41})y_{h1}(1-y_{h1}) · x_1$$
식에 out(1-out)의 형태가 있는데 이것을 델타식이라고 하고 은닉층의 숫자가 늘어도 계속해서 나타나게 되어 깊은 층의 계산도 가능합니다. 이 방법이 바로 오차 역전파라고 하고 이를 통해 딥러닝이 만들어집니다.
아직 문제가 하나 더 있습니다. 깊은 층을 만들다보니 역전파를 진행할 수록 기울기가 소실되고 가중치 업데이트가 출력층부터 시작해서 처음 층까지 전달되지 않는 현상이 생겨버립니다. 활성화 함수로 사용한 시그모이드 함수의 특성, '미분하면 0.25이여서 1보다 작으므로 계속 곱하다보면 0에 가까워지는 것' 때문입니다.

하지만 이후 여러 활성화 함수들이 연구되어 더 깊은 층을 만들 수 있게 되었습니다.

이렇게 경사하강법을 사용하는데 한 번 업데이트 할 때마다 전체 데이터를 미분하므로 속도가 느리고, 최적 해를 찾기 전에 최적화 과정이 멈출 수도 있습니다. 그래서 우리는 확률적 경사 하강법(stochastic Gradient Descent, SGD)를 사용하겠습니다. SGD는 전체 데이터가 아닌, 랜덤하게 추출한 일부 데이터만을 사용하기 때문에 빠르고 더 자주 업데이트할 수 있습니다.

모멘텀 확률적 경사 하강법(모멘텀 SGD)는 말 그대로 경사하강법에 탄력을 더해주는 것입니다. 기울기를 구하고 오차를 수정하기 전, 바로 앞의 수정 값과 방향(+, -)를 참고하여 같은 방향으로 일정한 비율만 수정되게 하는 방법입니다. 따라서 수정한 방향이 (+), (-)로 지그재그로 가는 현상이 줄어들고 관성 효과를 낼 수 있습니다. 현재로썬 정확도와 속도를 모두 향상시킨 아담(adam)이라는 고급 경사 하강법을 가장 많이 쓰고 있다고 합니다.
참고: [모두의 딥러닝]
'프로그래밍 > 인공지능' 카테고리의 다른 글
| k겹 교차 검증 (k-fold cross validation) (0) | 2023.07.08 |
|---|---|
| 모델 성능 검증 - 과적합(overfitting) (0) | 2023.07.03 |
| 다중 분류(multi classification) (0) | 2023.05.31 |
| 퍼셉트론(Perceptron) (0) | 2023.05.30 |
| 로지스틱 회귀 (0) | 2023.05.17 |



