전 글에선 모델의 성능을 검증해보았습니다.
학습을 최적화하기 위해 샘플을 학습셋 70%, 테스트셋 30%으로 나누었지만 이렇게 하면 30%의 샘플은 학습에 사용할 수 없다는 단점이 있습니다. 이를 해결하기 위한 방법이 k겹 교차 검증(k-fold cross validation) 입니다. 이것은 데이터셋을 여러 개로 나누어 하나씩 테스트셋으로 사용하고 나머지를 모두 합해서 학습셋으로 사용하는 방법입니다. 몇 겹인지에 따라 k의 수가 달라지는 것입니다. 이 방법으로 학습하면 모든 데이터가 학습셋이 되는 동시에 테스트셋이 될 수 있습니다. 갖고 있는 데이터의 활용성을 높이게 되는 것이죠
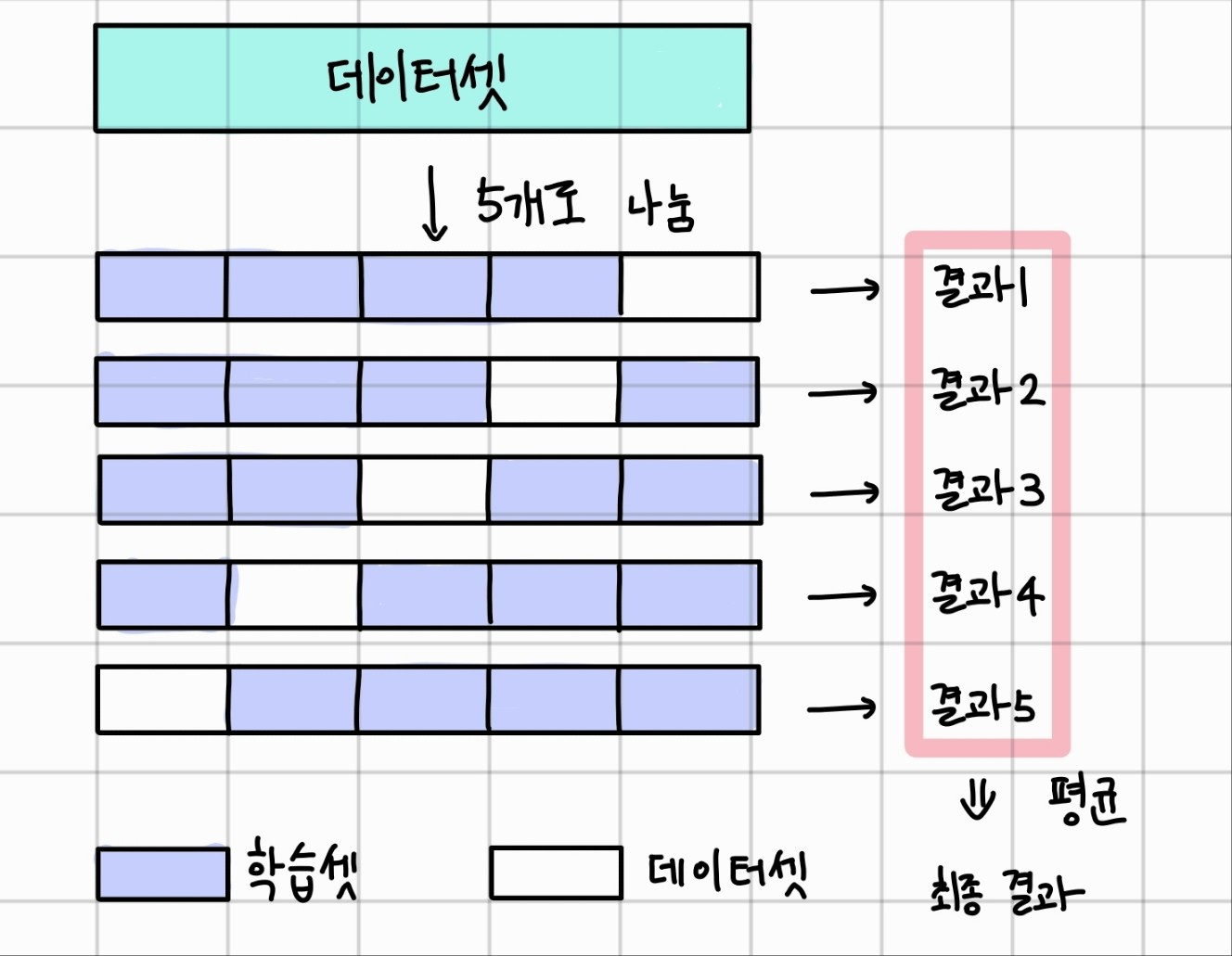
코딩을 해보겠습니다.
k겹 교차 검증 코드에는 데이터를 학습셋과 테스트셋으로 몇 번 나누어서 실행할 것인지 정해주어야 하는데 파이썬 사이킷런 라이브러리에 KFold() 함수가 데이터를 원하는 수만큼 나누어 각각 학습셋과 테스트셋으로 사용되게 합니다.
앞 글에서 코드를 가져와서 새로 추가해보겠습니다.
추가할 코드는 다음과 같습니다.
k=5 # 겹 수
kfold = KFold(n_splits=k, shuffle=True) #KFolde
acc_score = [] #정확도 리스트
for train_index, test_index in kfold.split(X):
X_train, X_test = X.iloc[train_index,:], X.iloc[test_index,:] #X의 학습셋, 테스트셋 나누기
y_train, y_test = y.iloc[train_index], y.iloc[test_index] #y의 학습셋, 테스트셋 나누기
model = model_fn() #딥러닝 모델 불러오기
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=200, batch_size=10, verbose=0)
accuracy = model.evaluate(X_test, y_test)[1] #정확도 구하기
acc_score.append(accuracy) #정확도를 리스트에 넣기
최종 코드 입니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
import pandas as pd
#데이터 불러오기
!git clne gttps://github.com/taehojo/data.git
df = pd.read_csv('./data/sonar3.csv', header=None)
X = df.iloc[:, 0:60] #음파 속성
y = df.iloc[:,60] #광물의 종류
#k겹 교차 검증
k=5 # 겹 수
kfold = KFold(n_splits=k, shuffle=True) #KFolde
acc_score = [] #정확도 리스트
#딥러닝 모델
def model_fn():
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
return model
#k겹 교차 검증으로 k번 학습
for train_index, test_index in kflod.split(X):
X_train, X_test = X.iloc[train_index,:], X.iloc[test_index,:]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
model = model_fn()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=200, batch_size=10, verbose=0)
accuracy = model.evaluate(X_test, y_test)[1] #정확도 구하기
acc_score.append(accuracy)
avg_acc_score = sum(acc_score) / k #정확도의 평균
#결과 출력
print('정확도: ', acc_score)
print('정확도 평균: ', avg_acc_score)변수 k로 몇 겹인지 설정해주고
KFold 함수를 불러와 샘플이 치우쳐지지 않도록 shuffle 해줍니다.
학습셋과 데이터 셋이 나누어지면 k번 반복해서 결과를 저장합니다.
실행 결과는 이렇게 나왔습니다.

오늘은 이렇게 k겹 교차 검증 방법을 실습해보았습니다.
공부를 하면서 인공지능 모델에 대해 알아가고 있는데 더 연습해서 모델을 직접 만들어 볼 수 있으면 좋겠습니다.
참고: [모두의 딥러닝]
'프로그래밍 > 인공지능' 카테고리의 다른 글
| CNN - 기본 프레임 (0) | 2023.07.19 |
|---|---|
| 합성곱 신경망(Convolutional neural network) - 데이터 전처리 (0) | 2023.07.19 |
| 모델 성능 검증 - 과적합(overfitting) (0) | 2023.07.03 |
| 오차 역전파와 활성화 함수 (0) | 2023.06.01 |
| 다중 분류(multi classification) (0) | 2023.05.31 |



